Analysis Request Flow
I’ll design the API in a very modular fashion (just like the entire project) to make it easy for us to add more options for the user later on. One of the options has to do something with the fact that all data generated from the scraping/analysis is saved to the database. The reason for that is optimization. If AAPL (Apple) was already analyzed 5 minutes ago it makes little sense to do an entire analysis from scratch again. Instead it will use the saved data from the previous analysis. This is done by combining a couple of options. I want to give the user the option to keep costs low by just accessing the already generated analysis from the database (if present) and not generating a new analysis at all.
For now let’s start by adding the FastAPI routes for the analysis generation. I’ll add a /check-analysis route which takes a GET request. It will take a ticker and title as queries.
For the reasons outlined above I now want to check if the inputted stock has been analyzed before so I’ll write a simple helper function to check and return if the ticker has been analyzed and the date on which it was analyzed. It will return an existing_analysis boolean and a message asking the user if the stock was analyzed before (and when) and ask if they want to create a new analysis.
Now I can add some synthetic data to the database, include and use postman to check if the endpoint works as expected.
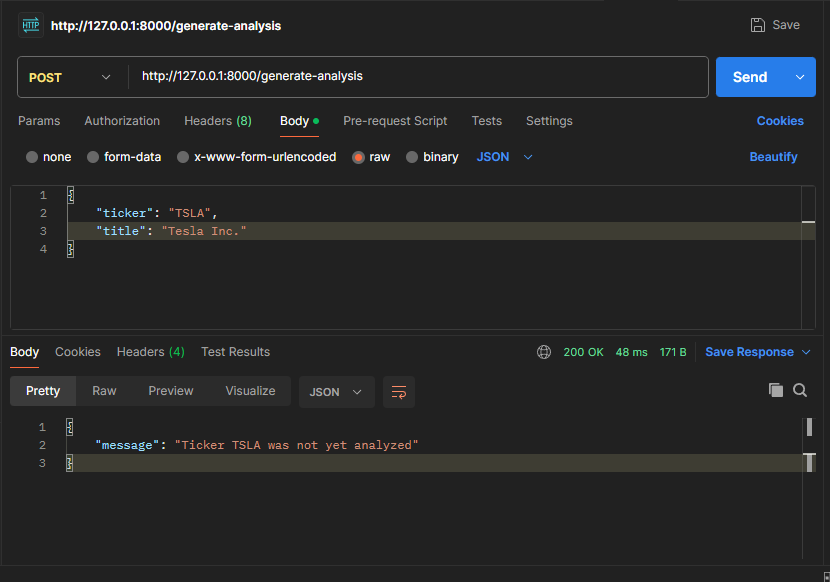 Image 1.1 The response with a ticker that is not in the DB
Image 1.1 The response with a ticker that is not in the DB
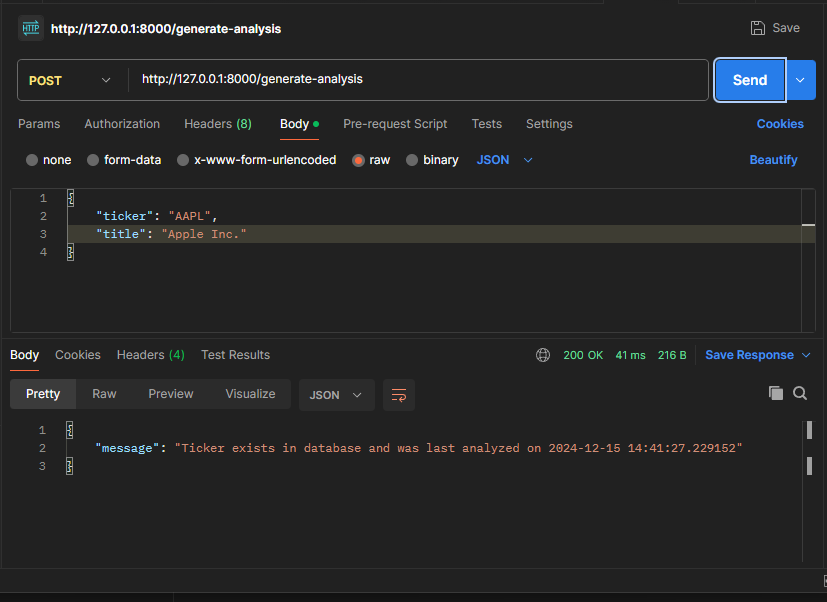 Image 1.2 The response with a ticker that is in the DB
Image 1.2 The response with a ticker that is in the DB
Starting analysis and updating Frontend
Next I’ll add a second endpoint that is going to get called when the user does want to create a new analysis after being prompted. This function will use FastAPI’s Background Tasks functionality to execute the start_analysis function asynchronously in the Background. start_analysis is then going to call all the other modules that together perform the analysis in the right order. Together with this endpoint I’ll also implement a dynamic loading screen which will tell the user at which point of the analysis the backend is currently at.
To update the Frontend on the current state the Frontend has to communicate with it in intervals. There’s two main options to build this. I could, for example, go for a bidirectional approach and use webhooks or Server-Sent events to send requests to the Frontend and update it. An easier and simpler option is to just use a polling strategy where I set up a second endpoint which will return the current state of the analysis when polled. I then combine this with the Frontend checking this endpoint in intervals. This is the better option since “live” updates aren’t really required for the application hence I don’t need to add an additional layer of complexity.
The flow should look like this:
- Start analysis (GET)
/generate-analysis?ticker=XYZ- Response will include a task id under which it’ll store the updates for the analysis:
"message": "Analysis for {ticker} started", "task_id": task_id, "status": "started"
- Response will include a task id under which it’ll store the updates for the analysis:
- Frontend calls (GET)
/analysis-status?task_id=1234in intervals.- Response will include the status updates:
"status": "Analysis started", "progress": 0, "ticker": ticker
- Response will include the status updates:
Old version
I’ll store the tasks in a very simple in-memory storage. This is not ideal for production. Ideally I would use something like redis to make sure progress doesn’t get lost in case the App crashes. However this would require setting up a separate redis server and this just isn’t worth the trouble right now, especially because this isn’t critical info but just basic progress updates.
I’ll create run_analysis.py which includes the start_analysis function. I’ll store the tasks as a Tasks dictionary with the keys being the task_id’s and the values being a dictionary including the status, progress and ticker.
Within this function I’ll just update the individual value of the key of TASKS after I run every individual analysis module which will be implemented later.
When an analysis is now started I’ll generate a UUID using pythons uuid library and initialize the task in store with a status of “pending”. Then the analysis gets generated via the aforementioned Background Tasks module and it returns the task_id to the Frontend.
I’ll then add the /analysis-status endpoint which imports the TASKS dictionary takes the task_id as query and uses it to return the correct Task value (if the task is found otherwise it’ll throw a 404).
New version (using redis)
I’m adding this part after having just deployed Episteme to production. I mentioned before that using an in memory storage for the tasks is not ideal for production. I initially had a few reasons in mind like error handling, keeping tasks alive and most importantly persistency across restarts.
However after deploying my app and getting a “Task not found” error when generating an analysis it hit me. The biggest issue in memory task storage would cause that I hadn’t even thought of. When deploying using a service like gunicorn or similar we want high availability for our web app. Therefore instances of the app load asynchronously and in their own states. Meaning memory is allocated individually which means the different instances don’t share the same memory space. This causes the worker responsible for fetching and returning the task status to the user not to have the same memory space as the worker responsible for keeping track of the tasks status in the first place.
This meant that when I deployed the app I had to migrate to redis if I wanted to or not. Luckily this was easier than I thought it would be. Since the task status isn’t a lot of data by itself and I plan to clean it from storage after the analysis is done I didn’t need a separate redis server or anything like that. Therefore I just integrated two helper functions which update and retrieve the task item from the redis storage. For this the task dictionary is loaded into and destructured to and from json to store it to redis in the expected format. I then just had to switch out all mentions of the TASKS dictionary with appropriate use of said helper functions. Lastly as I’v mentioned I want to clean the individual entries from the storage after the analysis is done. To do this I just provided the final update functions with an ex parameter which tells redis the TTL (time to live) for that entry. That way after the analysis is finished the task entry will only live for 15 seconds after which it expires and is cleared from storage (I put in 15 seconds to add some buffer for the frontend to render the updated state).
I wanted to add this paragraph so there’s no confusion when looking at the code since it’s now replaced with redis. To see the code before the changes to redis just have a look at the commit “switched from memory storage for tasks to redis” on the 9th of April 2025.