Text Embeddings
Introducing Embeddings
To overcome this limitation, I turned to text embeddings. Text embeddings represent textual information as high-dimensional numerical vectors. To generate these vectors, neural network models (trained on vast amounts of text data) learn contextual associations and semantic relationships between words and phrases. After extensive training, the model can translate any given sentence into a numeric vector. With the critical property that sentences with similar meanings will have vectors positioned closer together in the embedding space.
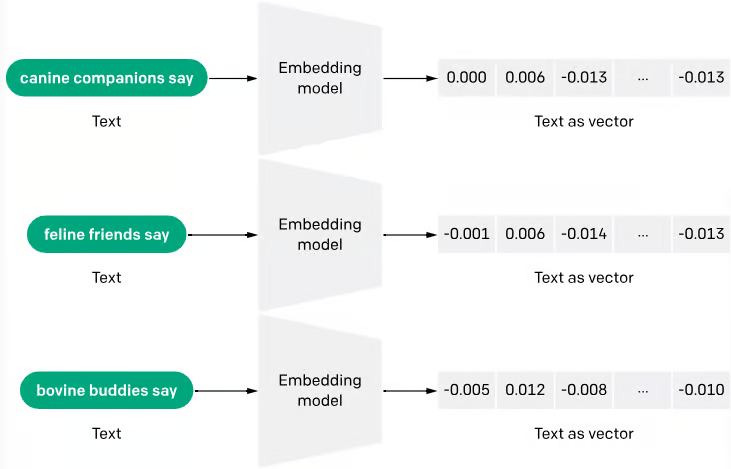 Image 3.1 This visual shows what the output of an embedding model looks like. If you look at the different weights of the embedding (the vector) you can see that the numbers are relatively close together (0.000, -0.001, -0.005) because the meaning of the three phrases is similar.
Image 3.1 This visual shows what the output of an embedding model looks like. If you look at the different weights of the embedding (the vector) you can see that the numbers are relatively close together (0.000, -0.001, -0.005) because the meaning of the three phrases is similar.
For example, take these example sentences:
- “Revenue increased by 10% in Q2”
- “Sales grew 10% in the second quarter”
They would generate embedding vectors located close together due to their semantic similarity. Visualizing how this “clustering” might look in a two dimensional space makes this concept pretty clear.
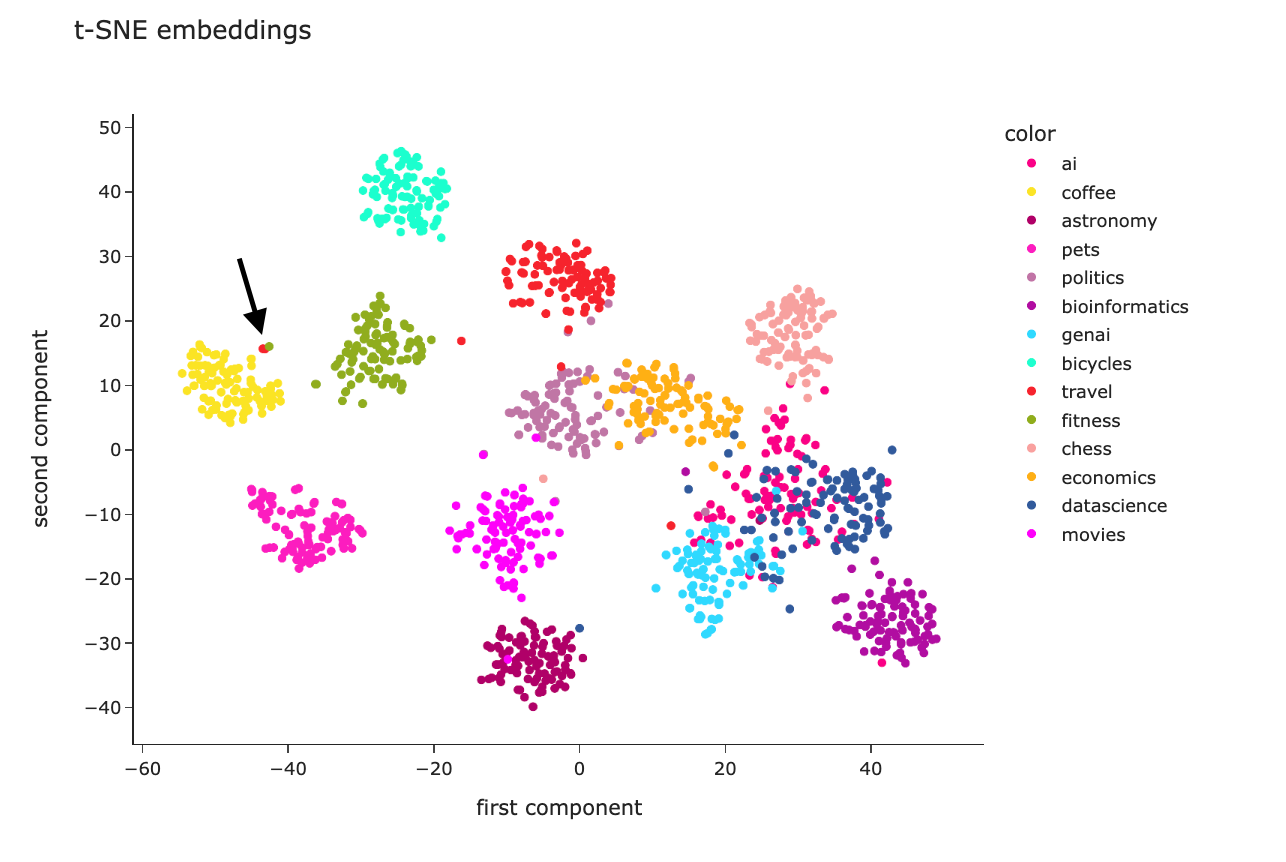 Image 3.2 Without even going into the more specific individual points it’s apparent here that similar topics are spatially close to each other. Politics and economics for example are very close together and even overlap at times while coffee and bioinformatics are further away from each other.
Image 3.2 Without even going into the more specific individual points it’s apparent here that similar topics are spatially close to each other. Politics and economics for example are very close together and even overlap at times while coffee and bioinformatics are further away from each other.