Filtering Existing Posts
Now that the data is scraped and it’s packed neatly in lists of dictionaries it’s time to return to an efficiency feature I have mentioned before. If the ticker has been analyzed before I don’t need to analyze the same posts again so I’ll crosscheck with the database to remove any posts that were analyzed before from the data.
First I’ll check if the ticker already exists in the database. If it does not it hasn’t been analyzed so I’ll just create a new ticker in the database so I don’t have to do it later and return the initial data back unchanged.
However if the ticker row is found the script start filtering. Now I’re gonna crosscheck the posts by comparing the URL’s of the scraped posts with the ones in the database. Now how do I do that most efficiently? Well one might think of just crosschecking by storing the scraped URLs in a list and then iterating over them to check if they’re in the database. But wait, if that person would have paid attention to Herr Weins Informatik Q3 Class you would have noticed this operation is O(n) time complexity. Now luckily I know a data structure that is much more appropriate and one of my favorite data structures in general. A set. Since sets work using a hash table under the hood and just calculate the hash of the variable and look it up in the internal table, using a set here leads to the operation working in O(1) time complexity.
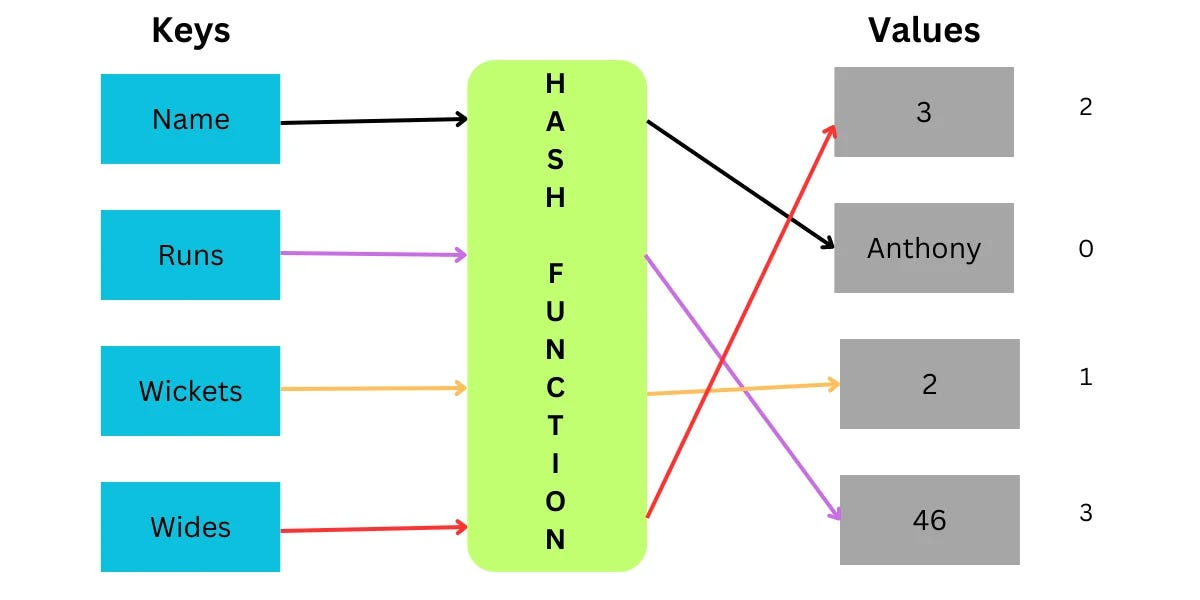 Image 2.1 An image to demonstrate graphically how sets work and why they’re useful here. Hash functions never return the same output for an input which leads to fast look-ups since one doesn’t have to iterate over the entire set if they know what they’re looking for. Instead they can calculate where the value would be stored based on the output hash and therefore check if it’s present at the according position in memory (this is also why hashes are used to encrypt passwords in databases, the companies themselves can’t see the users passwords but they can check if a given password is the correct one since they will both return the same hash).
Image 2.1 An image to demonstrate graphically how sets work and why they’re useful here. Hash functions never return the same output for an input which leads to fast look-ups since one doesn’t have to iterate over the entire set if they know what they’re looking for. Instead they can calculate where the value would be stored based on the output hash and therefore check if it’s present at the according position in memory (this is also why hashes are used to encrypt passwords in databases, the companies themselves can’t see the users passwords but they can check if a given password is the correct one since they will both return the same hash).
So I first gather all scraped URL’s in a set. Then I run a single SQL query to get all the links present in the Database that are also present in the scraped posts dictionaries. This, by the way, is the second advantage of using a set. Since SQLAlchemy has to convert the data I input to the query into a tuple, this way the app just needs to send one single query instead of building an inefficient for loop.
I then convert these existing links which I know to be duplicates into a set as well. I now run a for loop to compare these two sets with each other and remove all links that are present in both sets. And here it becomes apparent that if I had done this using a list this would be linear time complexity for each membership check. It’s easy to see how this adds up quite quickly. However since the script is comparing sets using under the hood hash calculation and tables it ends up with constant-time look-ups
Now I get that all these minuscule efforts at scraping just a little bit of efficiency off every operation seem overkill at first. The seem unimportant and likt they’re all just little changes only interesting for engineers. However they are not. An analysis will likely take a minute to maybe even a couple of minutes to finish. This is mostly because of the use of Large Language Model API’s. This is a pretty long time and since I cannot control how fast Open AI’s API will be I should focus on improving what we can control. And this means making everything as efficient as possible given the framework and knowledge so that all these little tweaks end up compounding into an overall faster experience.